Datadog Named Agent Sprawl. MCPProxy Is the MCP Fleet Inventory That Keeps It Traceable.
Algis Dumbris • 2026/05/05
In April 2026, Datadog published its State of AI Engineering report and named a problem the SRE community had been working around for the better part of a year. The headline finding: more than 70% of organizations now run three or more LLMs in production simultaneously. The secondary finding mattered more. Each additional model deployment compounded a class of operational complexity that traditional infrastructure tooling does not see and cannot inventory.
The community gave the pattern a name: agent sprawl.
Sprawl is the accumulation of agent infrastructure faster than the governance to track it. New models arrive, each with their own MCP servers. Coding agents discover and install servers autonomously. Developers wire up integrations from registries without filing approval tickets. Sub-agents spawn child sub-agents, each opening its own tool connections. The fleet expands. The inventory does not — because no one ever created one. The expansion was invisible at the moment it happened, and reconstructing it after the fact is harder than instrumenting it the first time.
Datadog’s prescribed response is conventional and correct: build a fleet inventory. Track server identity, framework, version, and the services each connected to. Make the inventory the source of truth for governance, not a derived artifact of after-the-fact log scraping. The same prescription has been applied to physical servers, virtual machines, containers, and Kubernetes pods over the last two decades. Each time, the lesson was the same: the inventory has to be created at the moment of admission, by the gate that admits the resource. Inventories assembled afterward are always incomplete.
For MCP specifically, the gate has to exist before the inventory can.
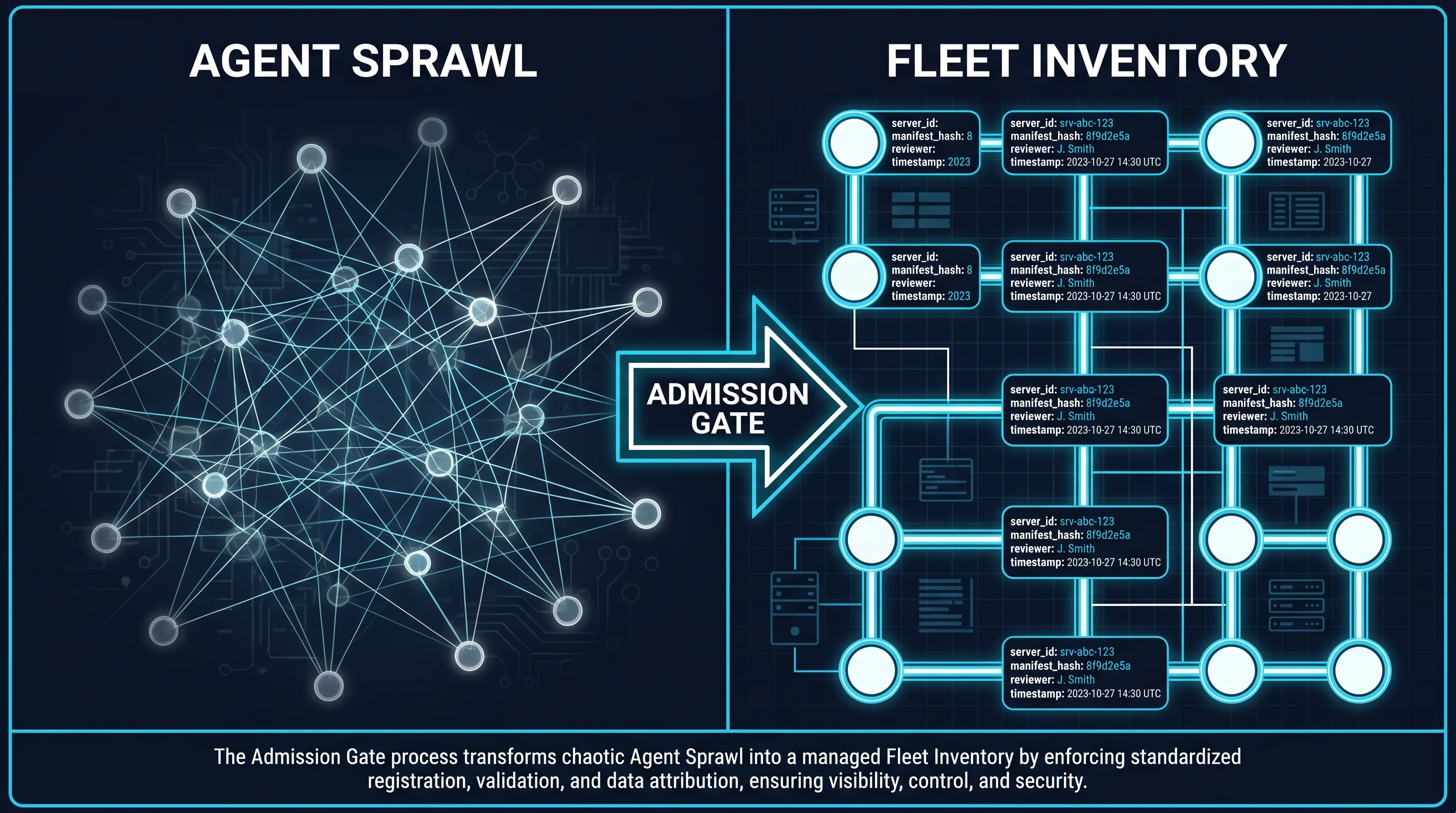
What Agent Sprawl Looks Like at the MCP Layer
The Datadog framing covers agents in the broad sense — any LLM-based system component, including the orchestration code, the model endpoint, the retrieval pipeline, and the tools the agent calls. The sprawl problem is most acute at the tools layer. That is where the proliferation compounds fastest, because every model deployment can independently provision its own MCP servers, every developer can add servers without coordination, and every coding agent that runs MCP-aware can install servers as a side effect of completing a task.
Three independent statistics from three different sources frame the size of the gap.
The Gravitee State of AI Agent Security 2026 report measured the institutional control side. Only 14.4% of organizations report complete security and IT approval coverage for their agent fleet. The remaining 85.6% have agents running without full approval. Where there are unapproved agents, there are by extension unapproved MCP server connections — every tool call those agents make goes through a server that no review process has signed off on.
The Datadog report measured the deployment density side. More than 70% of organizations run three or more models. Each additional model is, in practice, an additional MCP consumer. The sprawl multiplier is roughly linear in the number of models when each model deployment provisions its own tooling, which is the default in most enterprise stacks today.
The third number is the spawning multiplier. Gravitee’s same report found that 25.5% of agents in production have sub-agent spawning capability — they can invoke child agents to handle delegated subtasks. Every spawned sub-agent is, in turn, a potential MCP consumer. The connection graph is no longer flat. It is a tree, and the leaves multiply faster than the documentation can keep up.
The compounding math is the part that looks bad on a slide. Take the 70%-plus of organizations running multiple models. Multiply by the 85.6% with incomplete approval coverage. Multiply by the 25.5% with sub-agent spawning. The product is the share of organizations where the MCP connection graph is, by structural definition, partially invisible. The exact figure depends on how the populations overlap, but the order of magnitude is the same in every reasonable calculation: a substantial majority of enterprise AI deployments cannot enumerate their MCP servers on demand.
Fleet Inventory Is an Admission Record
Datadog’s fleet inventory prescription specifies what the record needs to contain: server identity, framework, version, the services each connected to, and the operational metadata required to answer questions about the fleet from a single source. For physical and virtual infrastructure, this inventory is created by the provisioning system. The hypervisor, the container runtime, the cluster controller — each is the gate through which a resource enters production, and each is therefore the right place to record the resource’s existence.
MCP has not had an equivalent gate. Servers connect through whatever client launches them — a coding agent, a chat interface, a workflow engine — and the connection event is recorded by no one in particular. The client knows it connected. The server knows it was connected to. Nothing in between captures the event in a form that a governance team can query.
MCPProxy’s admission gate is the equivalent gate. Every MCP server connection passes through the proxy. Every connection produces an admission record. The record is structured and complete by construction.
The fields map directly onto Datadog’s inventory specification:
- Server identity — the canonical name and source of the server, plus the originating registry or repository if the server was discovered through one.
- Manifest hash — a fingerprint of the server’s tool declarations and metadata at the moment of admission. This is the version field, but stronger: a manifest hash detects post-admission drift in a way that semantic version numbers do not.
- Tool declarations — the full list of tools the server exposed at admission, with their input and output schemas. This is the capability scope. It answers “what could this server do?” at the moment it was admitted, separately from “what did it actually do?” which lives in the call log.
- Reviewer identity — the human or automated process that approved the admission. This is the accountability field. Every admitted server has a name attached to its admission, not “unknown.”
- Approval timestamp — when the admission decision was made. This is the lifecycle field. Combined with later events — re-review, revocation, decommissioning — it forms the complete admission history of the server.
A row with these fields per admitted server is a fleet inventory in the sense Datadog prescribes. It is created at the admission event, not assembled afterward. It can be queried by any governance team that needs to answer “what MCP servers are in production, who approved them, and when?”

The Sub-Agent Problem
The sprawl multiplier most likely to surprise governance teams is the sub-agent spawning behavior Gravitee measured at 25.5%. A flat MCP deployment with one client and a handful of servers is tractable. A deployment where one agent spawns three sub-agents, and each sub-agent independently selects MCP servers from a registry, is not.
The sub-agent problem is structural in the same sense the original sprawl problem is structural. The spawn event is created by code, not by a person. There is no ticket. There is no approval workflow. The sub-agent comes into existence, opens its connections, completes its task, and disappears. If the connection events were not captured at the moment they happened, they are gone.
MCPProxy’s admission gate intercepts every MCP connection attempt regardless of who initiated it. A sub-agent attempting to connect to a new server triggers the same admission flow as the parent agent. Either the server is already admitted (and the new connection inherits the existing record), or it is not (and a new admission decision is required). The fleet inventory grows by one entry for each unique server, and the sub-agent’s connection is now part of the fleet record by the same mechanism that captured the parent’s connection.
This is what “structural” means in this context. The admission record is created by the act of connection, not by the agent’s compliance with a separately enforced policy. There is no opportunity for an agent to skip the inventory step, because the inventory step is a precondition for the connection itself.
What Datadog Cannot See, MCPProxy Can
Datadog’s report comes from a position of strength. They have one of the deepest views into production infrastructure in the industry, with telemetry data flowing in from a substantial fraction of the enterprise stack. The fact that even Datadog had to coin a name for the visibility gap — agent sprawl — says something specific about the nature of the gap.
Datadog sees what their agents send them. They see API calls, tool invocations, error rates, latency distributions, model usage by endpoint. What they do not see, by construction, is the moment a new MCP server connects for the first time, because that moment happens upstream of the telemetry layer. By the time the connection is producing observable behavior, the connection itself is already established. The admission event has already passed.
This is not a Datadog problem. It is the same problem any observability platform has when the thing being observed creates itself dynamically. Network firewalls solve this for IP traffic. Container runtimes solve it for container starts. Service meshes solve it for service registration. The general pattern is the same in each: a gate at the moment of admission, with the gate also serving as the inventory.
MCPProxy is the gate at the moment of MCP server admission. The admission event is the inventory entry. Everything Datadog observes about agent behavior afterward is more legible because the connections producing that behavior have an inventory entry attached.
The 91-Day Window
The agent sprawl framing intersects with a deadline that is already on every enterprise compliance team’s calendar. EU AI Act Article 12 enforcement begins August 2, 2026 — 91 days from the publication of this post. Article 12 requires automatic, lifetime logging of high-risk AI system behavior. The “lifetime” requirement starts at deployment.
For an MCP-using AI system to satisfy Article 12, the deployment event of every MCP server connected to the system has to be recorded. Sprawl is the structural reason this fails for most enterprises today: the deployment events were never captured, so there is nothing to retain, query, or produce in response to a regulator request.
Starting an admission gate now creates 91 days of admission records by the August 2 deadline. Starting on August 3 creates zero days of history at the compliance moment, with the six-month retention clock starting from a position behind. This is not a small difference. It is the difference between an enterprise that can produce a complete admission inventory on demand and an enterprise that has to explain to its regulator why the inventory does not exist.
What This Looks Like in Practice
The Datadog framing and the Gravitee numbers and the Article 12 deadline all converge on the same operational requirement. Enterprises running MCP-based AI systems need a structural fleet inventory of their MCP server admissions. That inventory has to be created at the moment of admission, not assembled afterward. It has to be complete, not sampled. It has to be queryable by people who do not write the agent code. It has to be retained for the lifetime of the deployment.
MCPProxy is one of the small number of components in the MCP ecosystem that operates at the right layer to produce this inventory. The admission record is the natural artifact of placing a quarantine gate between the agent and the MCP server. The inventory is a side effect of doing admission control correctly.
This is the part of the agent sprawl problem that does not require new research, new protocols, or new standards. The mechanism is the same one Kubernetes uses for pod admission, that container runtimes use for image admission, and that service meshes use for service registration. Place a gate. Record the gate’s decisions. The inventory creates itself.
The 91-day window is real, the sprawl numbers are measured, and the prescription is decades old. The only remaining question is whether the gate gets installed before the deadline or after.