The agents.txt Draft Just Expired. Here's Why It Doesn't Matter If You're Running MCPProxy.
Algis Dumbris • 2026/04/10
Today, April 10, 2026, draft-srijal-agents-policy-00 quietly expired. Six months on the shelf at the IETF Datatracker, no working group adoption, no -01 revision, no RFC stream assignment. The draft just ages out. The internet keeps moving. Nobody sends flowers.
If you’ve been following the “how should agents discover what they’re allowed to touch” debate, this was supposed to be one of the front-runners. It wasn’t. And for anyone running MCPProxy, it doesn’t matter.
Let me explain why.
What agents.txt Proposed
The idea was reasonable, which is partly why it got traction in discussion. A website publishes a policy file at /.well-known/agents.txt — same well-known URI pattern as security.txt or change-password — declaring what automated agents are permitted to do. Crawl these paths. Avoid those. Rate limits here. Authentication requirements there. A robots.txt for the AI agent era.
The analogy is obvious. The analogy is also the trap, but we’ll get to that.
The pitch was: agents read the file, respect the file, and the web gets an opt-in/opt-out mechanism for the flood of LLM crawlers, MCP clients, and autonomous workflows hitting servers that were never designed to be scraped by a Claude instance running overnight.
Fast community adoption in Twitter threads. Slow community adoption in the IETF process. You can probably see where this is going.
What Actually Happened
Individual submission. draft-srijal-agents-policy-00. Posted, discussed, never picked up by any working group. No -01 ever landed. Today the draft hit its six-month expiration window and was marked expired on the Datatracker.
https://datatracker.ietf.org/doc/draft-srijal-agents-policy/
Meanwhile, the rest of the “agent discovery and policy” space is a graveyard of overlapping proposals competing for oxygen:
draft-liang-agentdns— DNS-based agent discoverydraft-narajala-ans— Agent Name Servicedraft-zyyhl-agent-networks-framework— Agent Networks Framework- AI Agent Protocols Framework
- A2A Discovery proposals
- Agent manifest schemas
- And at least five more I’m not going to list because the list would double
Eleven-plus active drafts. Zero convergence. No working group has claimed this problem space. The IETF process is doing what the IETF process does when a community arrives with a dozen solutions before anyone has written down the problem.
Compare this to robots.txt, which was never an RFC at all until RFC 9309 — twenty-nine years after Martijn Koster proposed it in 1994. The web ran on a de facto standard that everybody respected out of politeness and a shared understanding that crawlers were mostly well-behaved. That social contract does not exist for AI agents. The politeness assumption has evaporated. The standards process hasn’t caught up, and based on today’s signal, it won’t for a while.
Why This Matters for Security
Here is the part that the standards debate keeps eliding. A policy file at /.well-known/agents.txt tells you what a server claims about itself. It doesn’t tell you whether the server is honest, compromised, or weaponized.
Discovery and trust are not the same thing.
If agents.txt had shipped, the workflow would have been: agent fetches the policy file, reads “this server permits tool calls from authorized agents,” marks the server as allowed, proceeds. The policy file is an attestation by the server operator. It is not a verification of the server’s behavior. It is not a check on whether the binary behind the endpoint is running malicious code. It is not a guarantee that the server isn’t exfiltrating your filesystem the moment you invoke its first tool.
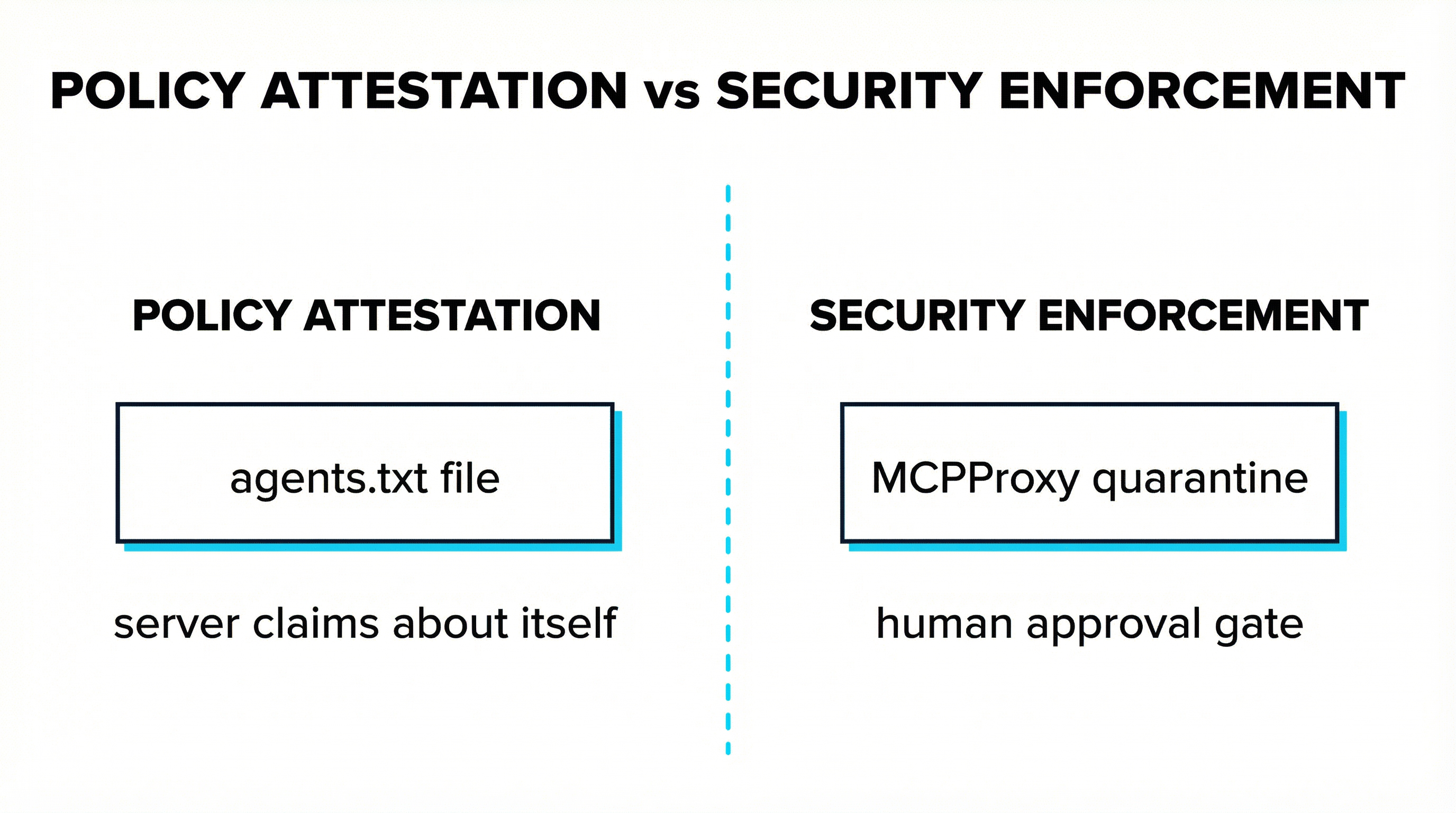
agents.txt would have been policy attestation. It would not have been security enforcement. Those are different layers, and the standards process keeps pretending they’re the same layer because it’s easier to write a well-known URI spec than it is to build a real trust pipeline.
We’ve already seen what trust-by-declaration gets you. Nine MCP CVEs in Q1 alone. Microsoft’s Azure MCP Server shipped without authentication (CVE-2026-32211). The first confirmed malicious MCP server exfiltrating credentials two weeks ago. Every one of those servers could have shipped a perfectly compliant agents.txt file describing its intentions. None of that file would have stopped the breach.
The Quarantine Insight
Here is what MCPProxy does, and why the agents.txt debate is architecturally irrelevant to it.
New server? Quarantined.
Server from the official MCP registry? Quarantined.
agents.txt-approved server, if agents.txt existed? Quarantined.
Anthropic’s own first-party filesystem reference server? Quarantined.
The human approval gate fires before any tool call executes, regardless of what any policy file, registry entry, vendor reputation, or .well-known URI says about the server’s trustworthiness. MCPProxy doesn’t ask whether a server claims to be safe. It requires a human to approve the tools before they’re callable. That’s it. That’s the gate.
Quarantine-by-default is not a compensating control for bad discovery. It is a different answer to a different question. The discovery question is “how do I find servers.” The quarantine question is “what do I do when I’ve found one.” MCPProxy answers the second question in a way that makes the first question’s answer almost irrelevant for security purposes.
What MCPProxy Actually Needs From Discovery
I want to be precise here, because “irrelevant” is too strong.
MCPProxy needs to know a URL to quarantine. That’s the entire discovery requirement. An endpoint, optionally some metadata, a way to add it to the quarantined pool. That’s a three-line config entry today. It’s a well-known URI tomorrow. It’s a DNS record the day after. It’s a registry API call after that. The mechanism doesn’t matter to the security model because the admission workflow — human approval, tool-by-tool — takes over the moment the URL hits the quarantine list.
Policy files would be nice-to-have metadata. They would not change whether a tool gets executed. The gate is still the human. The gate will always be the human until we have something better than “this server promises it’s not malicious” to base trust on, and agents.txt was never going to be that thing.
The Broader Ecosystem Signal
Eleven competing IETF drafts with no convergence is not a bug in the process. It’s a signal. It tells you that the community doesn’t agree on what problem it’s solving, let alone how. It tells you that the “how do agents discover servers” question will be unsolved for at least another 18 months, probably longer. Look at how long it took robots.txt to become RFC 9309 and then halve it if you’re feeling optimistic.
During those 18+ months, MCP servers will keep shipping. Some will be excellent. Some will be vulnerable. Some will be malicious. The CVE count will keep climbing. Enterprises will keep asking how to deploy MCP without handing attackers a foothold into their filesystems, credentials, and cloud APIs.
MCPProxy’s security posture does not change regardless of which (if any) discovery standard wins. Quarantine-by-default is not waiting on the IETF. It is not waiting on a well-known URI. It is not waiting on a registry consensus or a trust framework or a DNS proposal. It treats every server — new, old, vendor, community, official, malicious — the same way: locked until a human turns the key.
That’s the only trust model that works when the standards process is arguing with itself and the attackers are shipping faster than the RFCs.
The draft expired today. The gateway is still running. Nothing changed.
And that’s the point.