Pure BM25 Hits 14% Accuracy at Scale: What MCPProxy Needs Next
Algis Dumbris • 2026/03/19
The Number We Cannot Ignore
14%.
That is the Top-1 accuracy of pure BM25 when you point it at 916 MCP tools and fire natural-language queries at it. Not 14% on adversarial edge cases or trick questions — 14% on straightforward requests like “create a new employee record” or “list open support tickets.”
We have been honest from the start that MCPProxy uses BM25 for tool discovery because it is the right default for small-to-medium deployments: zero dependencies, sub-millisecond latency, fully deterministic. That position has not changed. But the benchmarks are now clear enough that pretending BM25 scales indefinitely would be dishonest. It does not.
This post breaks down exactly what the data shows, why BM25 degrades, and what MCPProxy is doing about it.
The Benchmark Data
Two independent evaluations published in early 2026 paint a consistent picture.
StackOne: 916 Tools, 2,700 Queries
StackOne’s benchmark tested tool discovery across 270 tools spanning 11 API categories (HRIS, ATS, CRM, Ticketing, IAM, Messaging, and more), generating 10 natural-language queries per tool for 2,700 total queries. The tool set was expanded to 916 tools for their scaled tests.
The results:
| Method | Top-1 Accuracy | Top-5 Accuracy | Latency |
|---|---|---|---|
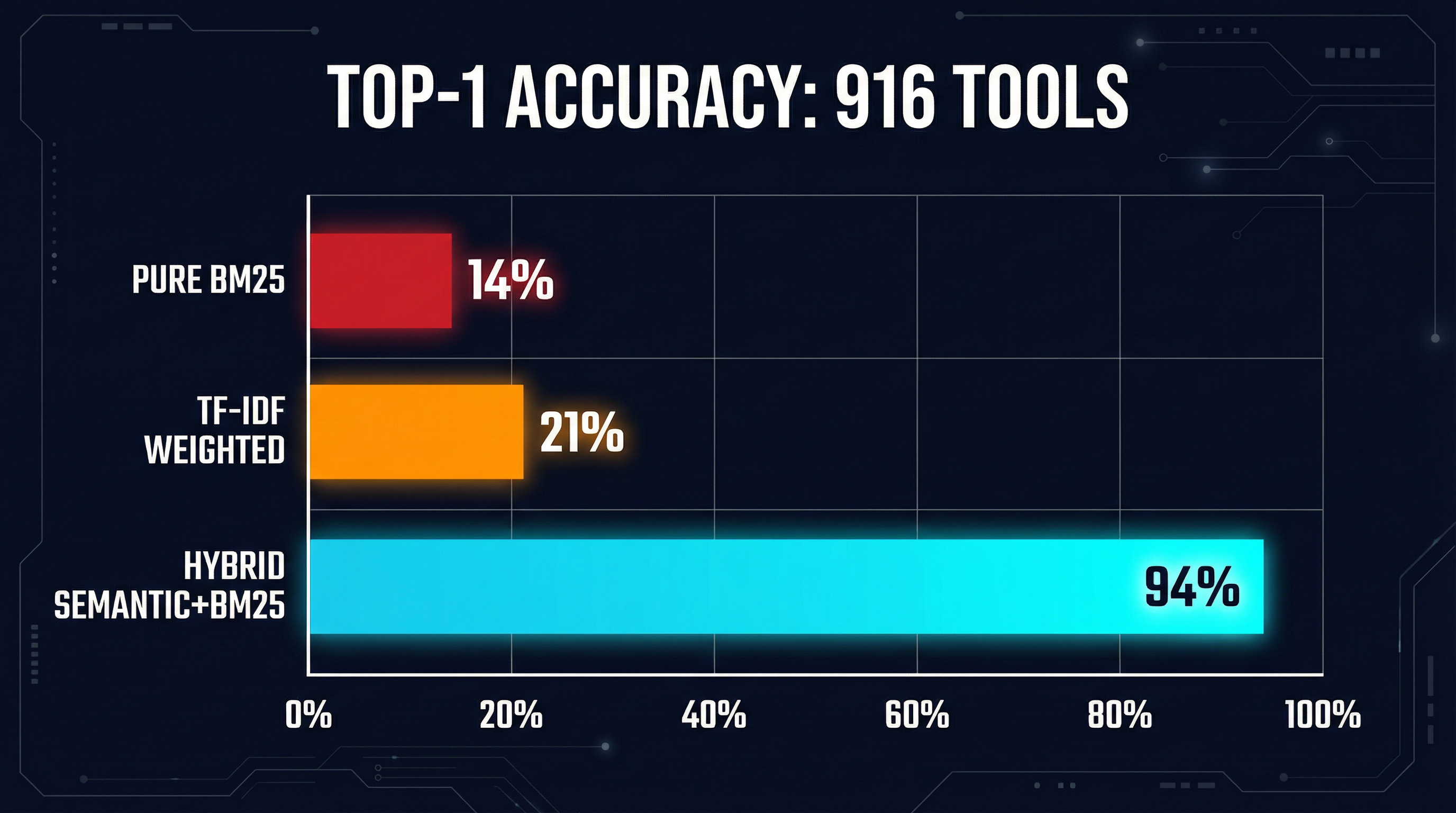
| Pure BM25 | 14% | 87% | <1ms |
| TF-IDF weighted | 21% | 90% | <1ms |
| Embedding search | 38% | 85% | 50-200ms |
| Reranker | 40%+ | 90%+ | 200-500ms |
The Top-5 number is worth pausing on. At 87%, BM25 almost always gets the right tool somewhere in the results. The problem is not that it misses entirely — it is that it cannot rank the correct tool first when hundreds of candidates share similar vocabulary.
Stacklok: 2,792 Tools, Hybrid vs. Pure
Stacklok’s MCP Optimizer evaluation ran a direct comparison across a larger tool set of 2,792 tools. Their hybrid semantic+BM25 approach was pitted against BM25-only and regex-based search.
| Method | Selection Accuracy | Avg Latency |
|---|---|---|
| BM25 only | 34% | <5ms |
| Regex-based | 30% | <5ms |
| Hybrid semantic+BM25 | 94% | 5.75s |
| Anthropic Tool Search (remote) | ~34% | 12-13.5s |
The gap between 34% and 94% on the same dataset is not incremental. It is the difference between a tool discovery system that works and one that guesses.
Why BM25 Breaks Down
Understanding why BM25 fails at scale matters more than the numbers themselves, because it tells us what to fix.
Common Verbs Saturate the Index
This is the primary failure mode. In a 916-tool corpus, action verbs like “create,” “list,” “get,” “update,” and “delete” appear in a large fraction of tool names and descriptions. BM25 uses Inverse Document Frequency (IDF) to downweight terms that appear in many documents. When “create” appears in 200 out of 916 tool descriptions, its IDF drops so low that it provides almost no discriminating signal.
The query “create a new employee” generates nearly identical BM25 scores for hris_create_employee, ats_create_candidate, crm_create_contact, iam_create_user, and dozens more. The term “create” is noise. The term “employee” is the only useful signal, and if the tool description says “add a new team member” instead of “employee,” even that signal vanishes.
Short Documents Kill Length Normalization
BM25’s document-length normalization (the b parameter) is designed to penalize long documents that match many terms simply by having more text. Tool descriptions are uniformly short — typically 10 to 50 words. When every “document” is roughly the same length, this normalization dimension collapses. BM25 loses one of its standard mechanisms for distinguishing relevant results from incidental matches.
No Semantic Understanding
BM25 is a lexical algorithm. It matches tokens, not meaning. When a user asks to “notify the team about a deployment,” BM25 looks for the literal tokens “notify,” “team,” and “deployment” in tool definitions. If the right tool is called slack_send_message with a description that says “post a message to a channel,” there is zero lexical overlap. BM25 scores it at zero. A semantic search would immediately recognize that “notify the team” and “send a message to a channel” describe the same action.
This is not a bug in BM25. It is a fundamental limitation of keyword search. The question is whether your tool set is small enough that lexical matching suffices, or large enough that semantic gaps become frequent.
The Threshold Is Around 100 Tools
Based on the data, the practical threshold where BM25 starts degrading noticeably is around 100 tools. Below that, tool names tend to be distinct enough that keyword matching works well. You might have one “create” tool per domain, and the domain-specific terms in the query easily disambiguate. Above 100 — especially above 200 — the verb overlap problem becomes severe, and the Top-1 accuracy drops sharply.
MCPProxy users today typically run 5 to 30 MCP servers with 30 to 150 tools total. Most are in the safe zone. But MCP adoption is accelerating, server registries are growing, and the trajectory points toward tool counts that BM25 alone cannot handle.
What Hybrid Search Actually Does
The term “hybrid” is not vague hand-waving. It is a specific, well-understood architecture.
Two Retrieval Paths in Parallel
When a query arrives, it runs simultaneously through two systems:
- BM25 path — keyword matching against the existing index. Sub-millisecond. Returns a ranked list based on term overlap.
- Semantic path — the query is embedded into a vector using a lightweight model, then compared via cosine similarity against pre-computed tool embeddings. Returns a ranked list based on meaning similarity.
Reciprocal Rank Fusion
The two ranked lists are merged using Reciprocal Rank Fusion (RRF):
RRF_score(tool) = 1/(k + rank_bm25) + 1/(k + rank_semantic)where k is a constant (typically 60). Tools that rank highly in both lists get the highest combined score. Tools that rank well in only one list still appear, but lower.
RRF is elegant because it works on rank positions, not raw scores. BM25 scores and cosine similarity values live on completely different scales. Trying to normalize and weight-average them is fragile. RRF sidesteps the problem entirely.
Why the Combination Works
The two paths complement each other at exactly the right failure points:
- BM25 nails exact matches. Query: “github create pull request.” BM25 immediately surfaces
github_create_pull_request. A semantic model might rank a conceptually similar tool from another service higher. - Semantic search handles paraphrasing. Query: “notify the team.” Semantic search connects this to
slack_send_message. BM25 returns nothing useful. - RRF ensures that when both signals agree, confidence is high. When they disagree, neither dominates.
This is why Stacklok’s hybrid approach hit 94%. It is not that either BM25 or semantic search alone is good enough — it is that their failures are uncorrelated, and combining them covers nearly all cases.
MCPProxy’s Three-Phase Roadmap
Here is how MCPProxy is evolving. Each phase builds on the previous one, and every phase maintains the core contract: single binary, zero required external dependencies.
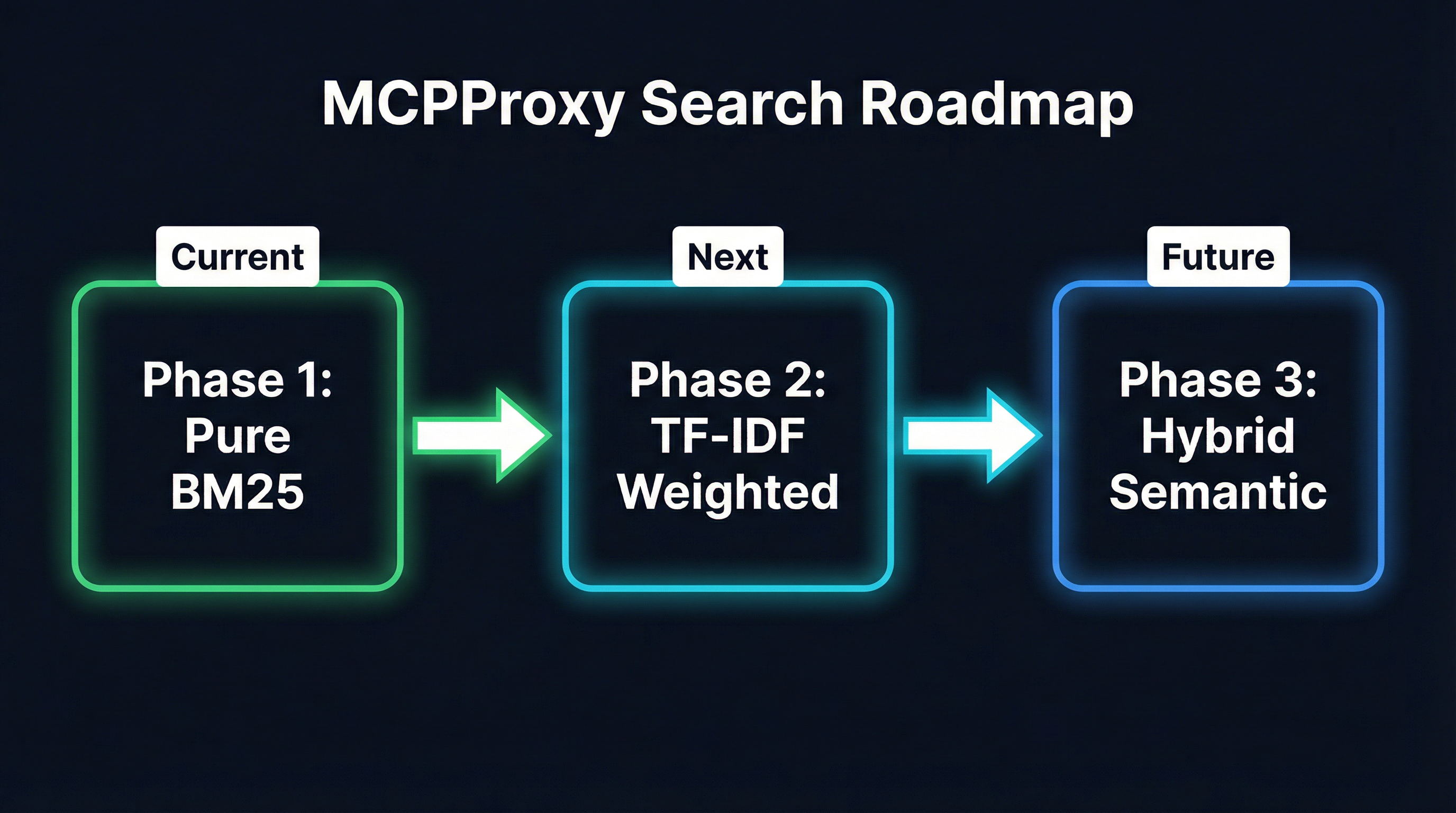
Phase 1: Pure BM25 (Current)
This is MCPProxy today. Tool discovery uses Bleve, an in-process Go search library, to build a BM25 index over tool names and descriptions. Queries return ranked results in sub-millisecond time.
What works well:
- Zero infrastructure. No embedding service, no vector database, no API keys.
- Deterministic and debuggable. You can inspect exactly why a tool ranked where it did.
- Fast re-indexing. When MCP servers connect or disconnect and tool lists change dynamically, the index rebuilds instantly.
- Strong accuracy for small tool sets. Under 100 tools, BM25 handles typical queries reliably.
What does not work well:
- Top-1 accuracy drops sharply beyond 100-200 tools.
- Common action verbs create a noise floor that overwhelms the signal.
- No semantic understanding means paraphrased queries fail silently.
MCPProxy ships with mcpproxy serve and tool discovery works out of the box at this phase. For the majority of current users, this is sufficient. We are not deprecating or replacing it.
Phase 2: TF-IDF Weighted BM25 (Next)
Before adding any embedding infrastructure, there is meaningful headroom in improving the BM25 pipeline itself. StackOne’s data shows TF-IDF weighting alone improves Top-1 accuracy from 14% to 21% — a 50% relative improvement with zero infrastructure changes.
Concrete changes planned:
Field-weighted scoring. Tool names carry more signal than descriptions. A query term matching in the tool name github_create_pull_request should be weighted higher than the same term appearing in a verbose description paragraph. Bleve supports per-field boosting natively; this is a configuration change.
Verb deweighting. Action verbs (“create,” “list,” “get,” “update,” “delete,” “search,” “find”) will receive artificially reduced IDF scores. This directly counteracts the saturation problem. When “create” is treated as a near-stopword, the remaining terms in the query carry more discriminating power.
Query expansion. Common abbreviations and synonyms will be expanded at query time. “PR” expands to also match “pull_request” and “pull request.” “Repo” matches “repository.” This bridges lexical gaps without requiring semantic understanding.
Server-context boosting. If recent tool calls have gone to GitHub tools, subsequent queries get a mild boost for GitHub-related results. This adds a simple contextual signal that improves accuracy in typical sequential workflows where a user works with one service at a time.
These improvements are implementable within the existing Bleve-based architecture. No new dependencies. No configuration changes required for users who do not want them. The default behavior simply gets smarter.
Phase 3: Hybrid Semantic+BM25 (Future)
For users scaling past 200 tools who need the jump from ~21% to ~94% accuracy, MCPProxy will offer an optional embedding path.
Local embedding models. Small, efficient models like all-MiniLM-L6-v2 (22M parameters, approximately 80MB) can embed tool descriptions locally in single-digit milliseconds. No API calls, no network dependency, no data leaving the machine. This preserves MCPProxy’s zero-phone-home guarantee.
Pre-computed embeddings. Tool descriptions rarely change. Embeddings will be computed once when a tool is registered and stored alongside the Bleve index. Re-embedding happens only when a tool’s description actually changes, which keeps the steady-state cost near zero.
Reciprocal Rank Fusion. BM25 and semantic results will be combined using RRF as described above. The implementation is straightforward — it is a scoring function over two ranked lists, not a complex ML pipeline.
Graceful degradation. If no embedding model is configured, MCPProxy falls back to BM25-only (Phase 1/Phase 2). Hybrid search is strictly opt-in. The zero-dependency default is preserved for users who value simplicity or operate in constrained environments.
Configuration will look something like:
search:
mode: hybrid # "bm25" | "hybrid" (default: "bm25")
embedding_model: local # "local" | "openai" | "ollama" (only when mode=hybrid)
rrf_k: 60 # RRF constant, default 60The goal is that a user who needs hybrid search adds two lines to their config and gets a 5-7x improvement in Top-1 accuracy. No Kubernetes cluster, no vector database, no recurring API costs.
Being Honest About the Tradeoffs
We would be doing a disservice if we presented this roadmap as purely upside. Here are the real tradeoffs:
Latency increases. BM25 runs in under a millisecond. Adding an embedding step — even with a local model — adds 5-50ms depending on hardware. For most MCP tool discovery workflows, this is imperceptible. But it is not zero, and for latency-critical applications, it matters.
Binary size grows. Shipping a local embedding model adds approximately 80-100MB to the binary or requires a separate download step. MCPProxy currently ships as a lean Go binary. We need to decide whether the embedding model is bundled, downloaded on first use, or provided by the user. Each option has UX implications.
Complexity increases. BM25 is simple to reason about and debug. Hybrid search adds a second retrieval path, a fusion algorithm, and potentially a model inference step. When something goes wrong, there are more places to look. We will need better observability and debugging tools to compensate.
The 94% number comes with caveats. Stacklok’s benchmark used a specific embedding model with specific tool descriptions. Real-world tool descriptions vary wildly in quality. Poorly written descriptions will reduce semantic search accuracy just as they reduce BM25 accuracy. Hybrid search is not magic — it is better matching on the same data.
None of these tradeoffs are deal-breakers. But they are real, and we want users making informed decisions about which search mode to use, not chasing a headline number.
What This Means for MCPProxy Users
If you have fewer than 100 tools: You are well-served by the current BM25 implementation. Phase 2 improvements will make it better, but you are unlikely to notice the difference in daily use. No action needed.
If you are growing toward 200+ tools: Start thinking about whether your query patterns hit the failure modes described above. If your tools span many domains with overlapping verbs, you will benefit from Phase 2 immediately and Phase 3 when it lands.
If you are building a large MCP deployment (500+ tools): Hybrid search is likely a requirement for you. Phase 3 is the target. In the interim, you can mitigate BM25’s limitations by writing distinctive tool descriptions that avoid generic verbs, and by using MCPProxy’s tool annotation system to pre-filter by category.
If you are evaluating MCPProxy against other solutions: Here is the honest comparison. Today, MCPProxy’s BM25 is competitive for tool sets under 100. For larger sets, solutions with built-in semantic search will outperform us on accuracy. Our Phase 3 roadmap closes that gap while preserving the zero-dependency, single-binary deployment model that no other solution offers.
The Broader MCP Ecosystem
MCPProxy is not operating in a vacuum. The entire MCP ecosystem is grappling with tool discovery at scale:
- Anthropic’s built-in tool search achieved about 34% accuracy in Stacklok’s benchmark — similar to standalone BM25. Their approach currently routes through a remote service, adding latency.
- Claude Code’s deferred tool loading reduces context footprint by presenting tool groups rather than individual tools. This is a complementary approach to search — reduce the candidate pool before searching it.
- The MCP specification community is discussing hierarchical tool management, reflecting consensus that flat tool lists do not scale past a few hundred entries.
The convergence is clear: everyone is moving toward some form of intelligent tool retrieval. The question is whether that intelligence lives in the model (via better prompting), in the protocol (via hierarchical specs), or in the proxy layer (via hybrid search). MCPProxy’s bet is on the proxy layer, because it keeps the intelligence close to the tools and does not depend on any specific model’s capabilities.
Conclusion
Pure BM25 hits 14% Top-1 accuracy at 916 tools. That is a fact, not a marketing problem to spin away. It is also a fact that BM25 works well for the tool counts most MCPProxy users have today, and that hybrid search reaches 94% when you need to scale further.
The path from 14% to 94% is not a mystery. TF-IDF weighting gets you to 21%. Semantic embeddings combined with BM25 via Reciprocal Rank Fusion get you the rest of the way. Each step is well-understood, implementable without exotic infrastructure, and compatible with MCPProxy’s core promise of a single binary with zero required dependencies.
We are building this in the open because transparency about limitations builds more trust than pretending they do not exist. If you are hitting BM25’s ceiling today, we want you to know there is a plan. If BM25 is working fine for your scale, we want you to know it will keep working — nothing is being taken away.
The benchmarks told us what we needed to hear. Now we build.
MCPProxy is open source at github.com/smart-mcp-proxy/mcpproxy-go. Install with brew install smart-mcp-proxy/tap/mcpproxy. Documentation at mcpproxy.app.