Perplexity's CTO Says MCP Eats Your Context Window — Here's How BM25 Discovery Fixes That
Algis Dumbris • 2026/03/18
TL;DR
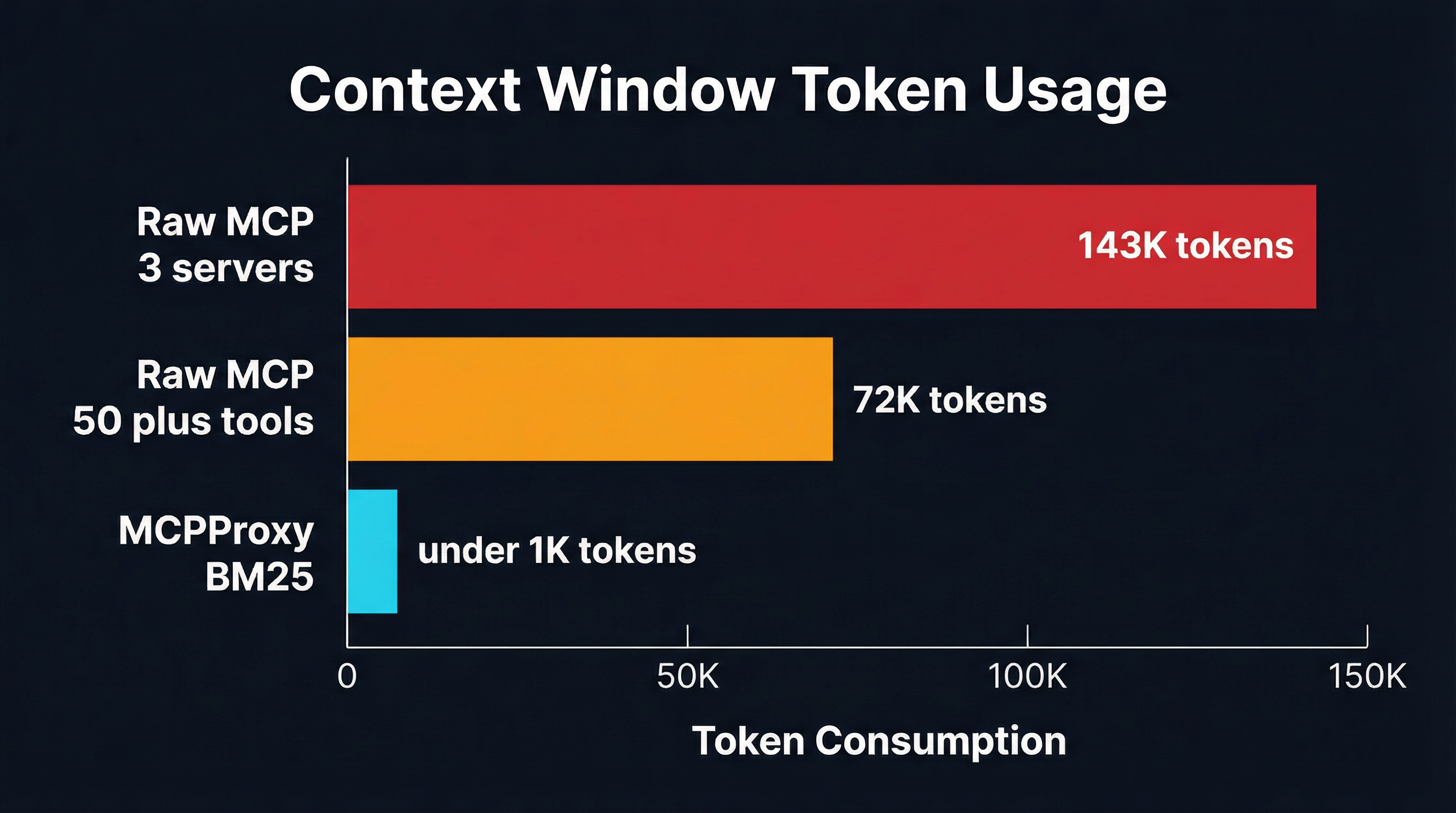
Perplexity’s CTO Denis Yarats recently explained why the company moved away from MCP for its agent infrastructure: every connected MCP server dumps its full tool catalog into the context window, burning tens of thousands of tokens before the model even begins reasoning. He is not wrong about the problem. But abandoning MCP entirely throws away the best interoperability standard the AI tooling ecosystem has produced. MCPProxy’s BM25 tool discovery was built to solve exactly this — a gateway layer that indexes every tool across every server and surfaces only the 3-5 relevant ones per query, taking a typical 54K-token tool catalog down to under 1K.

The Statement That Shook the MCP Community
When the CTO of one of the most visible AI companies publicly distances his product from a protocol that Anthropic, OpenAI, and Google have all endorsed, people listen. Denis Yarats did not mince words: MCP’s approach of loading every tool definition into the context window does not scale for production agent systems.
The reporting from Awesome Agents laid out the rationale clearly. Perplexity built their own Agent API with fixed, curated endpoints instead. No dynamic tool discovery. No schema injection. Just a clean, predetermined set of capabilities the model can call.
For Perplexity’s specific use case — a search product with well-defined tool needs — this makes sense. But the broader conclusion many drew, that MCP itself is the problem, misses the actual issue entirely.
MCP is not broken. The naive pattern of feeding every tool to every model call is what is broken.
The Math That Makes CTOs Nervous
Let us put actual numbers to the problem Yarats identified. These are not theoretical — they come from real MCP deployments measured across production systems.
A typical MCP server exposes 15-30 tools. Each tool definition includes a name, description, and a JSON Schema for its parameters. A moderately complex tool — think github_create_pull_request with its title, body, base branch, head branch, draft flag, reviewers, and labels — runs 400-800 tokens just for the schema.
Now scale that:
- 3 MCP servers (GitHub, Slack, Jira): ~50 tools, ~143K tokens for full tool definitions
- 10 MCP servers (a realistic developer setup): ~150 tools, ~200K+ tokens
- 50+ tools from a single enterprise MCP gateway: ~72K tokens just for schemas
Claude’s context window is 200K tokens. GPT-4’s is 128K. When your tool definitions alone consume 50-70% of the available context, the model has almost no room left for the actual conversation, retrieved documents, or chain-of-thought reasoning.
This is what a detailed analysis on Dev.to called “the silent tax” — you do not see it in your prompts, but it is there in every API call, eating your tokens and your budget.
The cost implications compound fast. At $15 per million input tokens (Claude Opus pricing), sending 143K tokens of tool definitions per request costs $2.15 per thousand calls just for the tool schemas. An agent that makes 50 tool-augmented calls per session is spending over $10 per session on tool definitions the model never uses.
Why “Just Use Fewer Tools” Does Not Work
The obvious response is: do not connect so many servers. Curate your tools. This is essentially what Perplexity did with their Agent API.
But this response misunderstands why MCP exists in the first place. The entire value proposition of the Model Context Protocol is dynamic tool discovery — the ability for an AI agent to connect to any compliant server and immediately use its capabilities without hardcoding. An agent that can only use a fixed set of tools is just a chatbot with API calls.
For production multi-agent systems, the tool ecosystem is inherently dynamic:
- New MCP servers come online as teams build internal tooling
- Tool capabilities evolve as servers are updated
- Different queries require different tool subsets — a code review task needs GitHub tools, not Salesforce tools
- Agent orchestration systems need access to a broad tool catalog while individual agents need narrow, relevant subsets
As HackTeam’s analysis points out, tool calling without server composition is fundamentally broken. You need access to many tools but you cannot afford to load them all. This is not a contradiction — it is an architecture problem with a known solution.
BM25 Discovery: The Architecture MCP Actually Needs
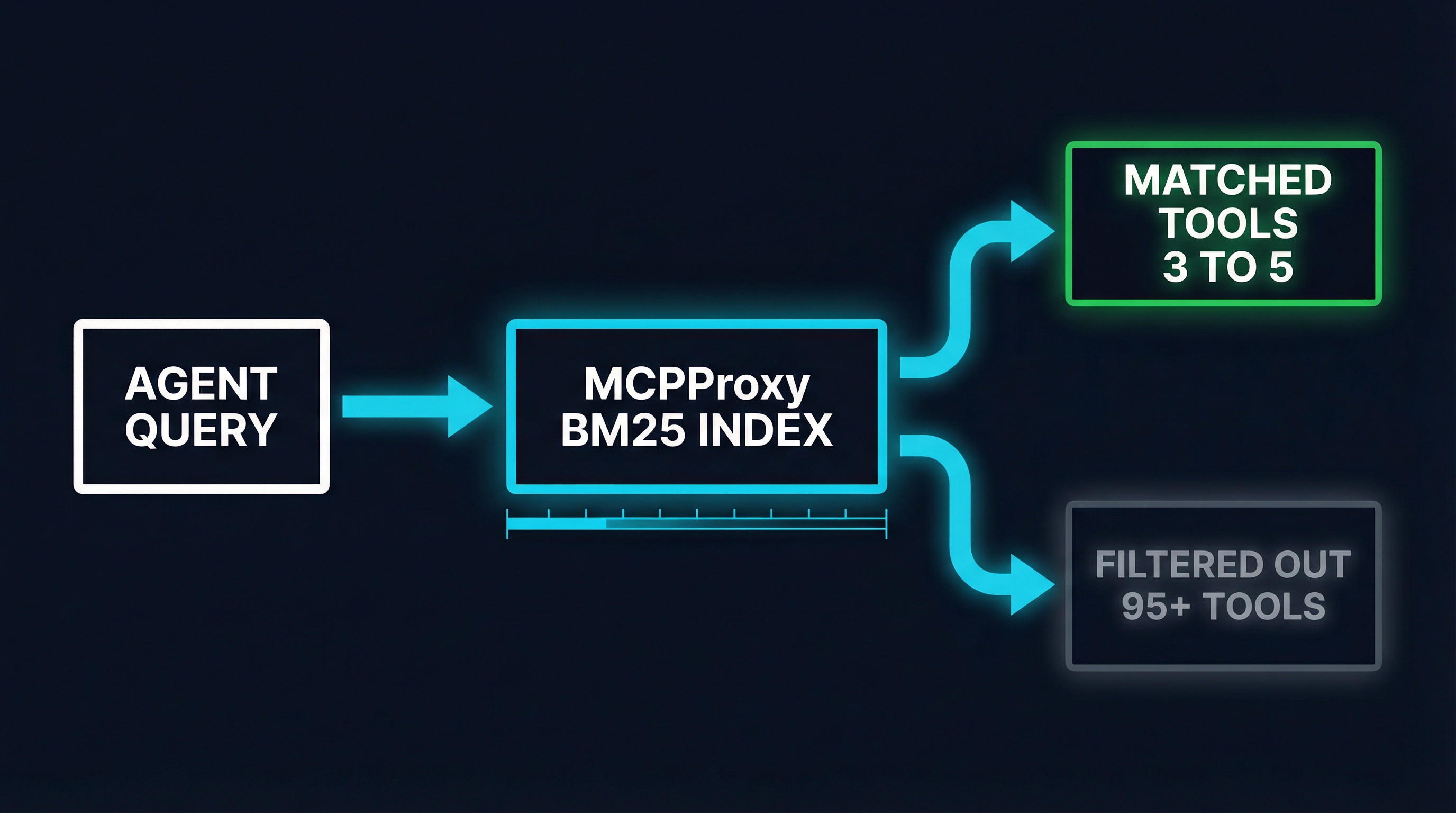
MCPProxy was built from the ground up around a single insight: the model does not need to see every tool. It needs to see the right 3-5 tools for the current query.
Here is how BM25 tool discovery works in practice.
Indexing Phase (Startup)
When MCPProxy starts, it connects to all configured MCP servers and retrieves their tool catalogs. Each tool’s name, description, and parameter schema are tokenized and indexed using BM25 — the same ranking algorithm that powered Google Search for its first decade and still underlies Elasticsearch, Apache Lucene, and most production search systems.
The index lives in-memory, built on the Bleve search library. No external dependencies. No vector database. No embedding model. The entire index for 500 tools fits in a few megabytes of RAM and builds in under a second.
Query Phase (Every Request)
When an agent sends a request through MCPProxy, the gateway:
- Analyzes the query to extract the user’s intent
- Runs the query against the BM25 index to rank all available tools by relevance
- Returns only the top-k matches (configurable, default 5) to the model
- Includes full schemas only for matched tools — everything else is invisible
The result: instead of 54K tokens of tool definitions, the model sees under 1K tokens of precisely relevant tools. The context window is preserved for what actually matters — the conversation, the retrieved context, and the model’s reasoning.
Why BM25 Specifically
BM25 is not the sexiest algorithm in the room. It is a term-frequency ranking function from the 1990s. But for tool discovery, it has properties that matter more than novelty:
Sub-millisecond latency. BM25 runs against an in-memory index. There is no network hop to an embedding service, no GPU inference, no vector similarity computation. Tool discovery adds effectively zero latency to the request.
Zero dependencies. No embedding model to host. No vector database to maintain. No API keys for a third-party service. MCPProxy ships as a single binary that runs anywhere.
Keyword precision for structured data. Tool names and descriptions are keyword-dense by design. github_create_pull_request is not a natural language sentence — it is a structured identifier where exact term matching is exactly what you want. BM25 excels at this.
Deterministic ranking. Given the same query and the same tool index, BM25 returns the same results every time. No embedding drift, no model version changes, no stochastic behavior. In production systems, predictability is a feature.
For tool catalogs up to several hundred tools, BM25 delivers top-5 accuracy above 87%, meaning the tool the agent actually needs is almost always in the returned set. For larger catalogs (1000+ tools), hybrid approaches combining BM25 with semantic search push accuracy to 94% — and MCPProxy is actively evolving in that direction.
What Perplexity’s Approach Misses
Perplexity’s Agent API is a reasonable engineering decision for their specific product. They have a well-defined search domain, a known set of capabilities, and a single-agent architecture where the tool surface is static and predictable.
But their approach has real limitations that become apparent in other contexts:
No dynamic discovery. When a new tool becomes available — say, a team ships a new internal MCP server for their deployment pipeline — the Agent API cannot discover it. Someone has to manually add the endpoint, update the client code, and redeploy. With MCPProxy, you add the server to the configuration, and every agent immediately has access to the new tools through the existing BM25 index.
Single-agent assumption. Perplexity runs one agent architecture serving one product. Enterprise and open-source ecosystems run many agents with different needs. A coding agent needs filesystem and git tools. A project management agent needs Jira and Confluence tools. A customer support agent needs CRM and ticketing tools. A fixed-endpoint approach requires building and maintaining separate tool configurations for each agent type. A gateway with discovery handles this naturally.
No composition. The real power of MCP emerges from server composition — combining tools from multiple servers into novel workflows the server authors never anticipated. An agent that can read a GitHub issue, query a database for related customer complaints, draft a response in Notion, and notify the team in Slack is using four MCP servers in concert. This kind of composition requires a broad tool catalog and intelligent selection, exactly what BM25 discovery provides.
Lock-in. Perplexity’s Agent API is proprietary to Perplexity. If you build on it, you are building on their platform, subject to their pricing changes, their API evolution, and their continued existence. MCP is an open standard with implementations from every major AI lab. MCPProxy is open source. The tool ecosystem built on MCP is portable.
The Real Lesson
Denis Yarats identified a genuine problem. Context window bloat from tool definitions is real, it is expensive, and it degrades model performance. Every serious MCP deployment has to solve this.
But the solution is not to abandon MCP. The solution is to stop treating every MCP server like it needs to dump its entire catalog into every model call.
The architecture pattern is straightforward:
- Gateway layer (MCPProxy) sits between agents and MCP servers
- Index everything at startup — know what tools exist across all servers
- Discover on demand — use BM25 to match queries to tools in sub-millisecond time
- Surface only what is relevant — send 3-5 tool schemas instead of 500
This is not a workaround. It is the correct architecture for tool-augmented AI systems, the same pattern that search engines, databases, and information retrieval systems have used for decades. You do not load every document into memory to answer a query. You index, you search, you retrieve.
MCP gives us the interoperability layer. BM25 discovery gives us the scaling layer. Together, they solve the problem Perplexity identified without sacrificing the dynamic tool ecosystem that makes MCP valuable.
Getting Started
MCPProxy is open source and takes about two minutes to set up:
# Install
go install github.com/smart-mcp-proxy/mcpproxy-go/cmd/mcpproxy@latest
# Add your MCP servers
mcpproxy upstream add notion https://mcp.notion.com/sse
mcpproxy upstream add fs -- npx -y @anthropic/mcp-server-filesystem /path/to/dir
# Start the gateway (BM25 discovery is on by default)
mcpproxy servePoint your AI client at MCPProxy instead of directly at your MCP servers. BM25 tool discovery happens automatically — only relevant tools reach the model. Your context window stays clean. Your token budget stays intact.
The next time someone tells you MCP does not scale, ask them if they have tried not sending every tool to every call. The protocol is fine. The naive integration pattern is what breaks. MCPProxy exists to fix exactly that.
MCPProxy is an open-source MCP gateway with BM25 tool discovery, quarantine-based security, and Docker isolation. Star the repo on GitHub or try it today.