Beyond BM25: The Future of MCP Tool Discovery
Algis Dumbris • 2026/03/15
TL;DR
In our earlier post, we made the case for BM25 as the right default for MCP tool discovery — and for small-to-medium tool sets, that case still holds. But new benchmarks from StackOne, Stacklok, and the RAG-MCP paper paint a more nuanced picture: BM25 alone delivers just 14% top-1 accuracy when tool counts climb past a few hundred. Hybrid approaches combining BM25 with semantic search hit 94%. This post lays out what the data actually shows, why BM25 degrades at scale, and how MCPProxy is evolving toward hybrid search while keeping the zero-dependency simplicity that makes it useful.
The Benchmarks Are In
Three independent evaluations have landed in the last few months, and they tell a consistent story.
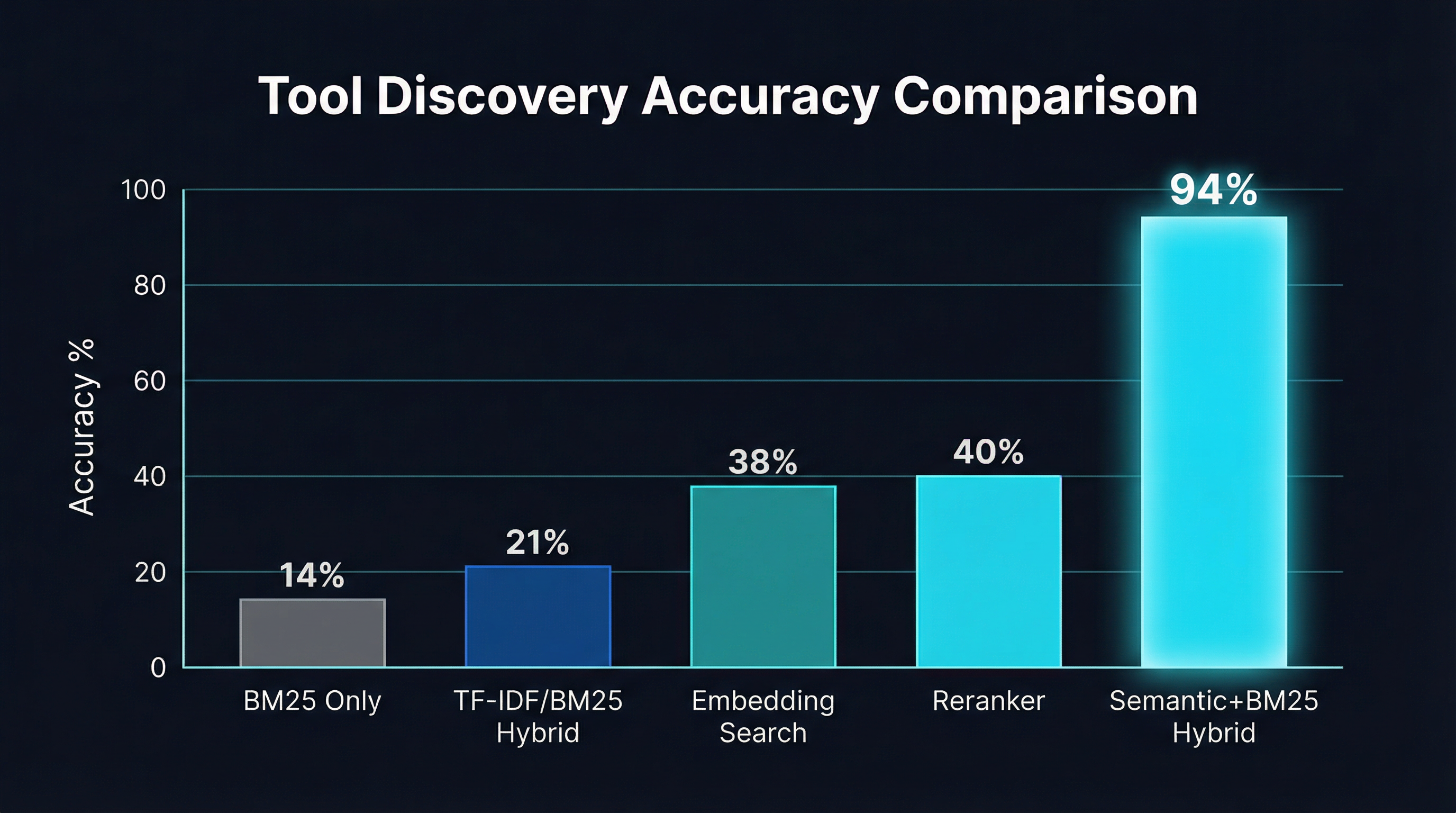
StackOne’s benchmark tested 270 tools across 11 API categories (HRIS, ATS, CRM, Ticketing, IAM, Messaging, and others) with 2,700 natural-language queries. Their findings:
| Method | Top-1 Accuracy | Top-5 Accuracy | Latency |
|---|---|---|---|
| BM25 only | 14% | 87% | <1ms |
| TF-IDF/BM25 hybrid (alpha 0.1-0.2) | 21% | 90% | <1ms |
| Embedding search | 38% | 85% | 50-200ms |
| Reranker | 40%+ | 90%+ | 200-500ms |
Stacklok’s MCP Optimizer ran a head-to-head comparison against Anthropic’s built-in Tool Search across 2,792 tools. Their hybrid semantic+BM25 approach achieved 94% selection accuracy versus 34% for BM25-only and 30% for regex-based search. The hybrid system also ran faster — 5.75 seconds average versus 12-13.5 seconds for Anthropic’s remote service.
The RAG-MCP paper confirmed what we already knew about the retrieval-first approach: agents given every tool upfront achieve just 13.6% accuracy, while retrieval-first routing more than triples it to 43.1%. But the paper also demonstrated that the retrieval mechanism itself matters enormously — not just whether you retrieve, but how.
Why BM25 Breaks Down at Scale
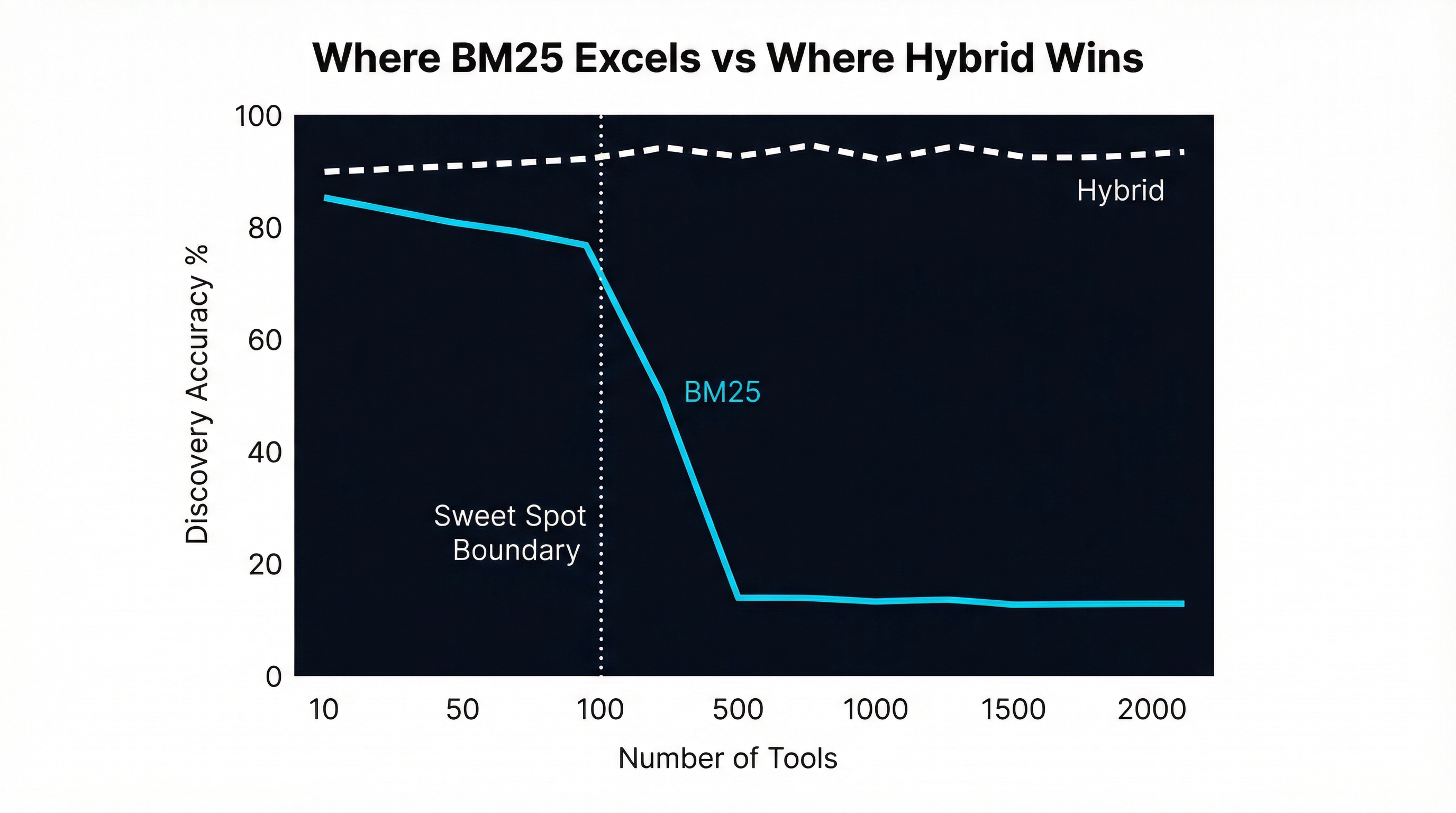
When we wrote the original BM25 post, we focused on a real and common scenario: 100-500 tools across 15-30 MCP servers. In that regime, BM25 genuinely works well. Tool names are descriptive, queries are keyword-heavy, and the term-frequency mechanics of BM25 reward exact matches effectively.
But the data shows a clear failure mode as tool counts grow. Here is what actually happens:
Common verbs saturate the index. When you have 2,000+ tools, verbs like “create,” “list,” “get,” “update,” and “delete” appear in hundreds of tool names and descriptions. BM25’s IDF (inverse document frequency) component is supposed to downweight common terms, but when 40% of your tools contain “create,” the discriminating power of that term drops to near zero. The query “create a pull request” matches github_create_pull_request, but it also matches jira_create_issue, slack_create_channel, notion_create_page, and dozens more — all with similar BM25 scores.
Short documents amplify the problem. BM25’s document-length normalization assumes documents vary meaningfully in length. Tool descriptions are uniformly short — typically 10-50 words. This collapses a dimension that BM25 normally uses for discrimination.
Semantic intent gets lost. A developer searching for “notify the team about a deployment” might need a Slack tool, a PagerDuty tool, or an email tool. BM25 cannot bridge the gap between “notify” and “send_message” or between “deployment” and the description of a CI/CD notification tool. It needs the exact keywords to appear in the tool definition.
None of this invalidates BM25 for smaller deployments. If you have 50 tools, the verb saturation problem barely exists — there might be three tools with “create” in the name, and BM25 easily distinguishes them by the other terms. The 87% top-5 accuracy from StackOne’s benchmark confirms that BM25 almost always gets the right tool somewhere in the results; it just struggles to rank it first when the candidate pool is large.
What Hybrid Search Actually Looks Like
The term “hybrid search” gets thrown around loosely. Here is the concrete architecture that the benchmarks show works:
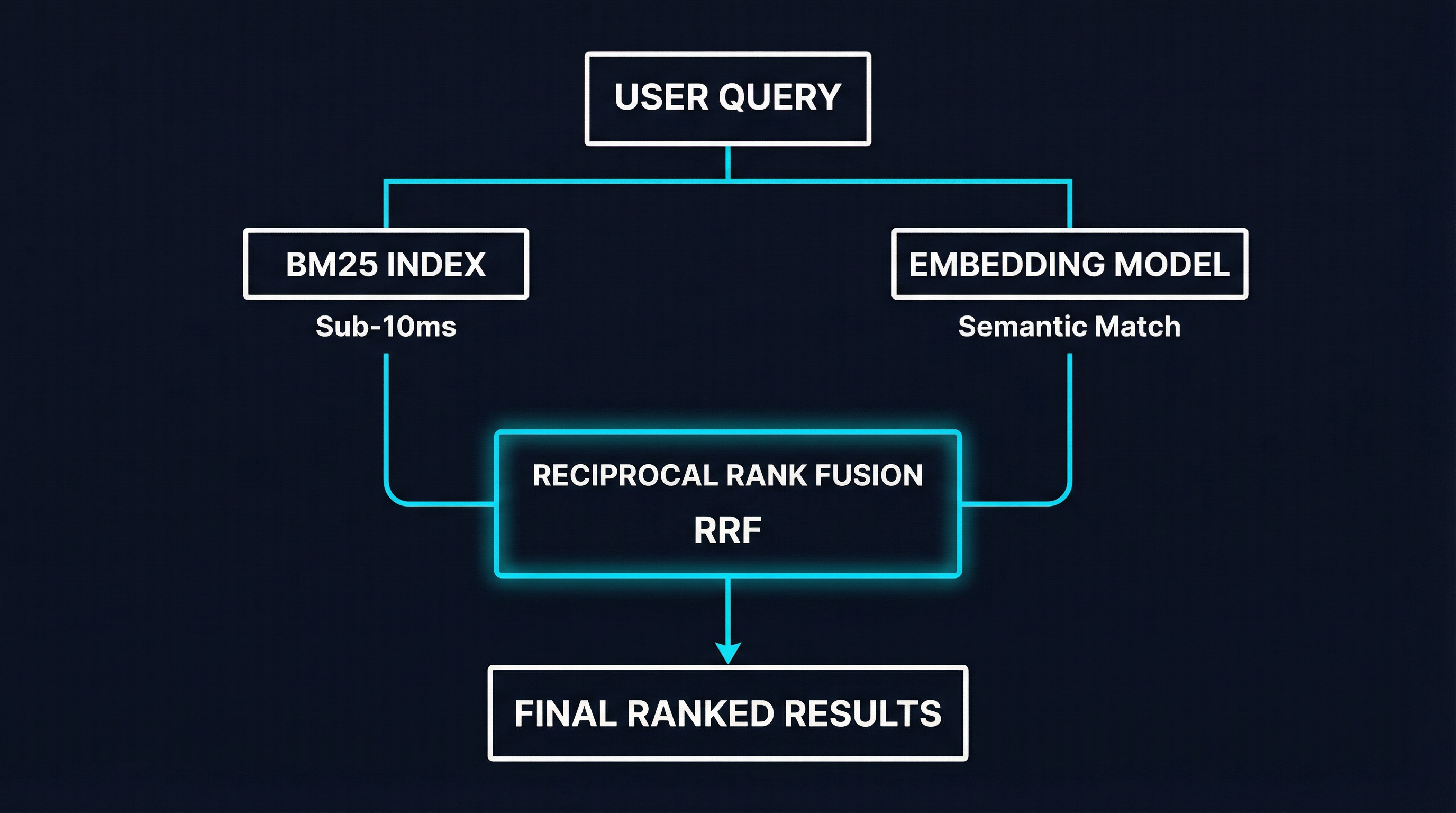
Step 1: Parallel Retrieval
The query runs simultaneously through two retrieval paths:
- BM25 path: The existing keyword search, running in-process against the Bleve index. Sub-millisecond, zero dependencies. Returns a ranked list of candidates based on term matching.
- Semantic path: The query is embedded using a lightweight embedding model, then compared against pre-computed tool embeddings via cosine similarity. Returns a ranked list based on semantic meaning.
Step 2: Reciprocal Rank Fusion
The two ranked lists are merged using Reciprocal Rank Fusion (RRF), a simple but effective algorithm. For each tool, RRF computes a combined score:
RRF_score(tool) = 1/(k + rank_bm25) + 1/(k + rank_semantic)where k is a constant (typically 60) that controls how much weight goes to top-ranked items. Tools that appear high in both lists get boosted; tools that rank well in only one list still appear but with lower combined scores.
RRF is appealing because it is score-agnostic — it works on rank positions, not raw scores. This matters because BM25 scores and cosine similarity scores are on completely different scales. Trying to normalize and weight-average them introduces tuning headaches. RRF sidesteps the problem entirely.
Step 3: Optional Reranking
For the highest accuracy, a lightweight reranker can rescore the top-N results from the fusion step. StackOne’s benchmarks show reranking pushes top-1 accuracy to 40%+, but at significant latency cost (200-500ms). For most MCP tool discovery workloads, the RRF output without reranking is sufficient.
Why This Works So Well
The two retrieval paths complement each other precisely where each is weak:
- BM25 excels at exact term matching: “github_create_pull_request” for the query “create pull request github.” Embeddings might rank a semantically similar but wrong tool higher.
- Embeddings excel at semantic bridging: “notify the team” maps to
slack_send_messageeven though the words do not overlap. BM25 would miss this entirely. - RRF ensures that when both signals agree, the result is high-confidence. When they disagree, neither signal alone dominates.
Stacklok’s 94% accuracy versus BM25’s 34% on the same 2,792-tool dataset is the strongest evidence: the combination is not just incrementally better — it is categorically better at scale.
The Ecosystem Is Converging on This
MCPProxy is not the only project rethinking tool discovery. The ecosystem is converging on a set of related ideas:
Claude Code’s deferred tool loading already implements a form of hierarchical discovery. With approximately 200 tools across 8 MCP services, Claude Code presents only top-level service groups in the system prompt. The model drills down on demand, loading individual tool schemas only when needed. This reduces context footprint from approximately 200 entries to approximately 8 — a different axis of the same problem.
GitHub’s MCP Server ships with configurable toolsets — static allow-lists that let administrators expose only the tool groups relevant to a given agent. When no toolsets are specified, defaults are used. This is configuration-time filtering rather than runtime discovery, but it addresses the same root cause: too many tools in the context window.
The MCP specification itself is evolving. Discussion in the community around hierarchical tool management reflects growing consensus that flat tool lists do not scale. Estimates suggest 50 tools consume 20-25K tokens; at 200+ tools, you are spending the majority of your context window on tool definitions before the conversation starts.
Philipp Schmid at Hugging Face has recommended “vector retrieval to dynamically select and present only the most relevant tools” — essentially describing the architecture MCPProxy is moving toward. The argument is straightforward: as the tool ecosystem grows from dozens to thousands of available MCP servers, static approaches break down.
Where BM25 Still Wins
Honesty demands acknowledging that hybrid search is not always the right answer. BM25 retains clear advantages in several scenarios:
Small-to-medium tool sets (under 100 tools). If you are connecting 5-15 MCP servers with a total of 30-100 tools, BM25’s 87% top-5 accuracy is excellent. The verb saturation problem barely exists at this scale. The zero-dependency, sub-millisecond profile makes it the obvious choice.
Air-gapped and offline environments. BM25 runs entirely in-process with no network calls. Embedding models require either an API call or a local model. For environments where network access is restricted or latency to an embedding service is high, BM25 remains the only viable option.
Determinism and debuggability. BM25 scoring is fully transparent. You can inspect exactly why a tool ranked where it did — which terms matched, what their IDF weights were, how document length normalization affected the score. Embedding similarity scores are opaque by comparison. When a user reports that the wrong tool was selected, debugging BM25 is straightforward.
Cold start speed. BM25 indexes are built instantly from tool metadata. Embedding every tool description requires either API calls (adding latency and cost) or running a local model (adding memory and compute requirements). In MCPProxy’s dynamic environment — where servers connect and disconnect, and tool lists change in real time — fast re-indexing matters.
MCPProxy’s Roadmap: Hybrid Without Compromise
Here is how we are thinking about evolving MCPProxy’s tool discovery without sacrificing the properties that make it useful today.
Phase 1: Smarter BM25 (Now)
Before adding embedding infrastructure, there is significant headroom in improving the BM25 pipeline itself:
- Field-weighted scoring. Tool names should carry more weight than descriptions. A match on the tool name
github_create_pull_requestis stronger signal than a match in a verbose description paragraph. Bleve supports per-field boosting natively. - Verb deweighting. Common action verbs (“create,” “list,” “get,” “update,” “delete”) should receive lower IDF scores than they naturally get. This counteracts the saturation problem directly.
- Query expansion. When a query contains “PR,” expand to also match “pull_request” and “pull request.” This bridges common abbreviations without needing semantic understanding.
- Server-context boosting. If the user’s recent tool calls have been against the GitHub server, boost GitHub tools in subsequent searches. This adds a simple contextual signal.
These improvements target the gap between 14% and 21% top-1 accuracy — the range where StackOne showed that lightweight hybrid approaches (TF-IDF + BM25 weighting) deliver meaningful gains with zero infrastructure changes.
Phase 2: Optional Embedding Layer
For users who need higher accuracy at scale, MCPProxy will offer an optional embedding path:
- Local embedding models. Small, fast models like
all-MiniLM-L6-v2(22M parameters, ~80MB) can embed tool descriptions locally in single-digit milliseconds. No API calls, no network dependency. - Pre-computed embeddings. Tool descriptions change infrequently. Embeddings can be computed once at index time and stored alongside the Bleve index. Only re-embed when a tool’s description actually changes.
- RRF fusion. Combine BM25 and embedding results using Reciprocal Rank Fusion, keeping the implementation simple and score-normalization-free.
- Graceful degradation. If the embedding model is not configured, MCPProxy falls back to BM25-only. No user is forced to adopt the embedding path. The zero-dependency default remains intact.
Phase 3: Hierarchical Discovery
For very large deployments (500+ tools, 50+ servers), hierarchical discovery reduces the search space before retrieval even begins:
- Server-level grouping. Present tool categories (e.g., “GitHub,” “Slack,” “Database”) as a first-level filter. The agent selects a category, then searches within it.
- Progressive disclosure. Start with coarse groups, drill down to individual tools on demand. This mirrors Claude Code’s deferred tool loading pattern.
- Dynamic tool sets. Automatically group tools by server, by annotation (read/write/destructive), or by usage patterns. An agent working on a code review task gets coding tools surfaced first.
The Guiding Principle
Every phase maintains MCPProxy’s core contract: it ships as a single binary with zero required external dependencies. The embedding layer is opt-in. Hierarchical discovery uses local state. Nothing phones home. Nothing requires an API key to function. The simplest deployment — download the binary, point it at your MCP servers, and go — continues to work exactly as it does today.
What This Means for You
If you are running MCPProxy today with fewer than 100 tools, nothing changes. BM25 is serving you well, and the improvements in Phase 1 will make it even better.
If you are scaling toward hundreds or thousands of tools, the hybrid roadmap means you will not need to swap out MCPProxy for a different solution. The same proxy that handles your 20-tool setup today will handle your 2,000-tool setup tomorrow, with the same operational simplicity.
If you are evaluating tool discovery approaches, here is the honest summary:
| Your Scale | Recommended Approach | Expected Top-1 Accuracy |
|---|---|---|
| 10-50 tools | BM25 (MCPProxy default) | ~80-85% |
| 50-200 tools | BM25 with field weighting | ~60-70% |
| 200-500 tools | Hybrid BM25 + embedding | ~85-90% |
| 500+ tools | Hybrid + hierarchical discovery | ~90-94% |
Conclusion
The earlier BM25 post was not wrong — it was incomplete. BM25 is the right starting point for tool discovery: zero infrastructure, sub-millisecond latency, deterministic results, and strong accuracy for the tool counts most users have today. But the data is clear that BM25 alone does not scale to the hundreds-or-thousands-of-tools future the MCP ecosystem is heading toward.
The good news is that hybrid search is not an all-or-nothing proposition. BM25 and semantic search are complementary, not competing. Reciprocal Rank Fusion combines them cleanly. Local embedding models eliminate the infrastructure concerns we raised in the original post. And progressive, hierarchical discovery addresses the context-window problem from yet another angle.
MCPProxy started with BM25 because it was the right engineering choice for the constraints at hand. It is evolving toward hybrid search because the constraints are changing. The tool ecosystem is growing, the benchmarks are telling us where the limits are, and we would rather share that data honestly than pretend a single algorithm solves everything forever.
That is the engineering approach: measure, acknowledge the data, and build the next thing.
MCPProxy is open source and available at github.com/smart-mcp-proxy/mcpproxy-go. Install with brew install smart-mcp-proxy/tap/mcpproxy. Full documentation at mcpproxy.app.