Automated Testing for AI Agents: How to Build Regression Tests for MCP Tools
Algis Dumbris • 2025/08/27
TL;DR: Testing AI agents with tools is fundamentally different from traditional software testing due to non-deterministic behavior. This post surveys current approaches for evaluating Model Context Protocol (MCP) tool quality, and demonstrates how these methods are implemented in our open-source mcp-eval utility, built for evaluation of mcpproxy project. We cover trajectory-based evaluation, similarity scoring, and practical Docker-based testing architectures that handle the inherent variability of LLM systems while maintaining testing reliability.
Introduction
Testing AI agents that use external tools presents unique challenges that traditional software testing cannot address. Unlike deterministic functions with predictable outputs, LLM-based agents produce variable responses even with identical inputs. This non-determinism makes manual testing insufficient and exact-match assertions brittle.
| Traditional Software Testing | AI Agent Testing |
|---|---|
| Deterministic outputs | Non-deterministic responses |
| Exact match assertions | Semantic similarity scoring |
| Single execution path | Multiple valid solution paths |
| Binary pass/fail | Graded similarity metrics |
| Input/output validation | Trajectory and reasoning validation |
MCP tool evaluation requires new methodologies that embrace variability while maintaining reliability standards. This has led to the development of trajectory-based evaluation frameworks that assess not just final outcomes, but the entire decision-making process of AI agents.
Background and Challenges in Testing LLM-Powered Tools
Non-determinism in LLM Agents
Large language models introduce randomness even with “deterministic” settings. Atil et al. (2024) found accuracy swings of up to 15% across repeated runs of the same model on identical tasks, with performance gaps between best and worst runs reaching 70%. This creates fundamental challenges for traditional testing approaches:
| Deterministic Systems | Non-Deterministic LLM Systems |
|---|---|
| Same input → Same output | Same input → Variable outputs |
| Reproducible failures | Inconsistent failure patterns |
| Linear debugging path | Complex prompt-model interactions |
| Fixed test assertions | Probabilistic evaluation needed |
| Single execution sufficient | Multiple runs required for confidence |
Statistical and Trajectory-Based Solutions
Researchers have developed methodologies that embrace non-determinism rather than fighting it. The RETAIN framework introduces “Metric Tolerance” with users identifying 2x more errors through interactive evaluation. AgentBoard (NeurIPS 2024) provides fine-grained progress metrics for multi-round interactions. Blackwell et al. (2024) demonstrate that uncertainty quantification and prediction intervals (x̄ ± ε) are essential for reliable LLM evaluation.
Tool Discovery and Selection Challenges
MCP tools are described by JSON schemas and natural language descriptions. Testing must verify multiple failure points: agents may fail to discover relevant tools, select wrong tools due to overlapping functionality, or construct parameters incorrectly. Research shows loading all tools yields only ~13% accuracy in tool selection, while retrieving relevant subsets raises accuracy to 43%, highlighting the importance of effective retrieval mechanisms.
MCP-Eval: A Practical Implementation
We developed MCP-Eval, an open-source system that implements these research insights for practical MCP tool evaluation. Built around the MCPProxy architecture, it evaluates agent behavior through end-to-end scenarios using retrieve/invoke functions.
Architecture and Design
The system runs scenarios in baseline vs current modes, capturing complete conversation trajectories for comparison. Key components include:
Claude Code Python SDK Integration: MCP-Eval uses the Claude Code Python SDK as its dialog execution engine. Beyond standard API key authentication, the SDK supports subscription tokens, making it ideal for small projects and non-commercial open-source initiatives where API costs might be prohibitive.
Docker-First Isolation: MCPProxy runs in containers with state reset protocols, ensuring reproducible test conditions and security isolation.
Scenario-Driven Testing: YAML-defined test cases representing real user intents and expected tool usage patterns.
name: "Search MCP Tools (Simple)"
description: "Simple test to find environment-related tools"
enabled: true
user_intent: "Find tools for environment variables"
expected_trajectory:
- action: "search_tools"
tool: "mcp__mcpproxy__retrieve_tools"
args:
query: "environment"
success_criteria:
- "Found environment-related tools"Comprehensive Logging: Every message, tool call, parameter, and response is captured with timestamps and git version tracking.

Similarity-Based Trajectory Evaluation
The core innovation moves beyond brittle exact matching to semantic similarity assessment:
Enhanced Argument Similarity:
arg_similarity = (key_similarity × 0.3) + (value_similarity × 0.7)This weighted approach evaluates structural compatibility (parameter shapes) and content similarity (values), prioritizing semantic meaning while ensuring structural consistency. Value similarity uses word-based Jaccard for strings, distance-based metrics for numbers, and character frequency cosine similarity for JSON objects.
Multi-Dimensional Scoring:
- Trajectory Similarity: Overall dialogue alignment through message-by-message comparison
- Tool Invocation Analysis: Per-call similarity scoring with Exact Match (1.0), Partial Match (0.1-0.9), or Mismatch (0.0) labels
- MCP-Only Filtering: Focus on actual tool interactions (mcp__*), excluding framework overhead
- Visual HTML Reports: Side-by-side comparisons with color-coded similarity indicators
Case Study: Environment Variable Tool Search
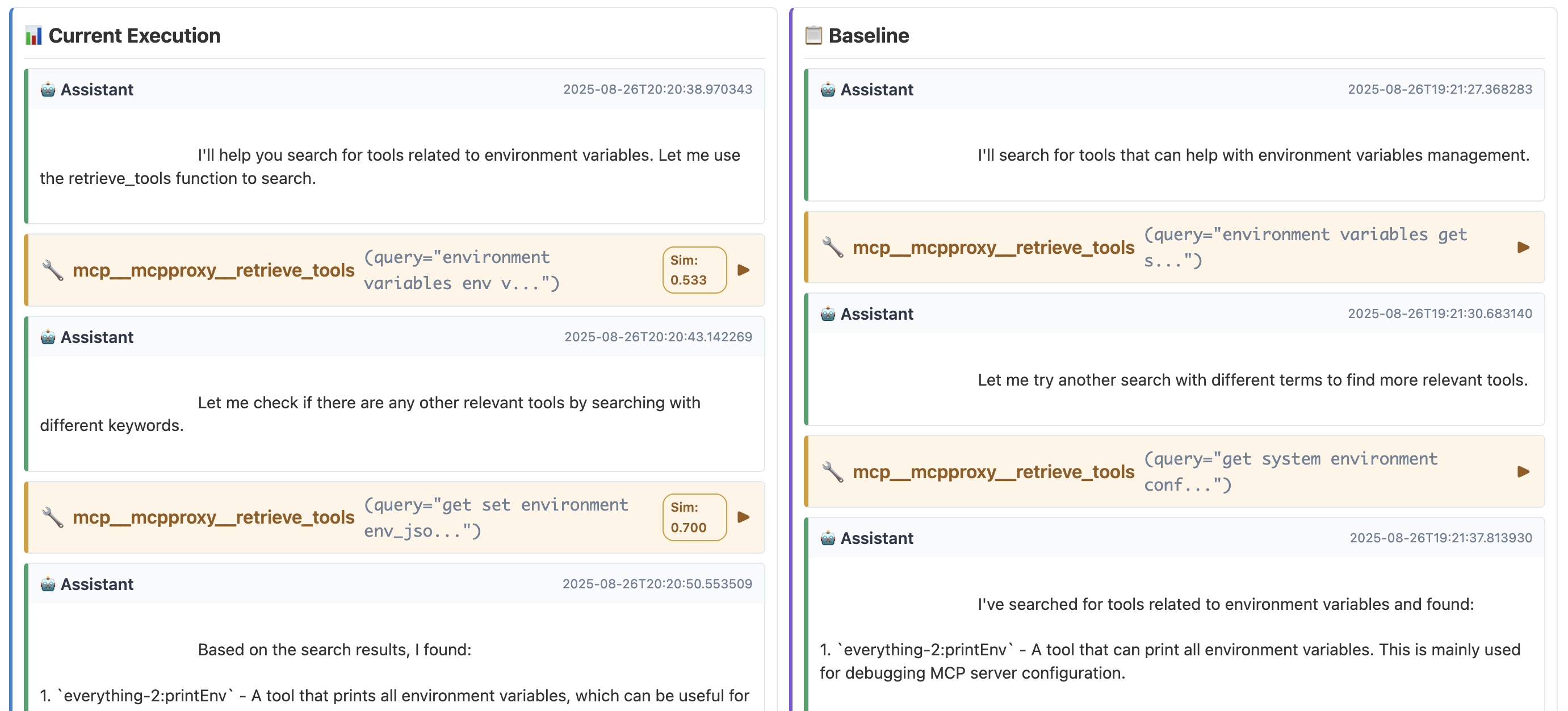
Real evaluation comparing baseline vs current execution demonstrates the system’s practical value.
Scenario: User asks to “Find tools for environment variables” Expected: Agent should discover and recommend the printEnv tool
Full report: 📊 Environment Variable Tool Search - Comparison Report
Execution Comparison
Baseline: retrieve_tools(query="environment variables get set manage env vars") → found printEnv, offered 3 user options
Current: retrieve_tools(query="environment variables env var configuration") → found printEnv, offered 2 user options
Results Analysis
- Overall Score: 0.693 (good similarity despite variations)
- Trajectory Score: 0.617 (moderate difference in dialogue flow)
- Invocation 1: 0.533 similarity (same tool, similar query)
- Invocation 2: 0.700 similarity (better query alignment)
Key Insights: System correctly identified semantic equivalence between query variations (“env vars” ≈ “environment variables”), handled UX changes (3→2 options) as acceptable variation rather than failure, and maintained focus on core functionality (tool discovery worked consistently).
Example Reports: View actual MCP-Eval HTML reports demonstrating these comparisons:
- 📊 List All Servers - Comparison Report (shows baseline vs current execution)
- 📋 List All Servers - Baseline Report (baseline execution details)
Related Research and Implementation Context
Academic Evaluation Frameworks
Recent conferences have produced sophisticated frameworks moving beyond simple success metrics:
ToolSandbox (NAACL 2025): First benchmark with stateful tool execution and implicit state dependencies. Provides Python-native testing environment applicable to MCP systems requiring persistent context.
UltraTool (ACL 2024): Evaluates entire tool utilization process across six dimensions. Focus on dynamic tool discovery aligns with MCP’s philosophy.
Berkeley Function-Calling Leaderboard (BFCL): Industry standard with 2,000 question-answer pairs across multiple programming languages. BFCL v3 includes multi-step, parallel execution methodologies adoptable by MCP systems.
Statistical Validation Best Practices
Research converges on key approaches for AI system evaluation: property-based testing for behavioral patterns, semantic similarity with configurable thresholds (0.7-0.9), and pass@k metrics revealing that even GPT-4o drops from ~85% success to ~25% when tasks repeat eight times. These findings align with broader research on dialog evaluation metrics that emphasize the need for multi-dimensional assessment beyond simple accuracy measures.
Docker Isolation Architecture
MCP-Eval uses Docker-first architecture addressing critical production requirements:
State Isolation: Fresh containers eliminate tool cache contamination and connection state leakage between runs.
Security Containment: Tool execution constrained within isolated environment.
Reproducible Results: Identical test conditions across development machines and CI/CD pipelines.
Host Machine MCPProxy Container
┌─────────────────────────┐ ┌──────────────────────┐
│ Claude Agent (Python) │────►│ MCPProxy Go Binary │
│ Test Scenarios (YAML) │ │ MCP Server │
│ HTML Reports │ │ Tool Discovery │
└─────────────────────────┘ └──────────────────────┘Visual Reports and Analysis
MCP-Eval generates comprehensive HTML reports with side-by-side conversation comparisons, expandable tool calls with JSON payloads, color-coded similarity badges, and git version tracking for regression debugging.
Live Report Examples: Explore interactive HTML reports generated by MCP-Eval:
- 📊 Server Comparison Report - Side-by-side baseline vs current execution with similarity scoring
- 📋 Baseline Execution Report - Detailed trajectory analysis with tool call breakdowns
- 🔒 Security Analysis Report - Quarantined server inspection and security evaluation
These reports demonstrate the visual analysis capabilities described above, with expandable sections, color-coded similarity metrics, and comprehensive logging that enables effective debugging and quality assessment.
Conclusion
Automated structured evaluation is essential for reliable AI agents using external tools. The non-deterministic nature of LLM systems demands new methodologies that embrace variability while maintaining quality standards. MCP-Eval demonstrates how to adapt evaluation techniques from software testing and NLP research for AI agent systems through trajectory comparisons, similarity-based scoring, Docker isolation, and visual reporting.
The system transforms unpredictable LLM behavior from a liability into a quantifiable parameter, enabling systematic regression testing that catches issues early and measures progress objectively. This cultural shift from manual testing to automated evaluation frameworks provides the foundation needed for production-grade AI systems.
Open-sourcing these methodologies through mcp-eval source code enables community contributions and shared best practices. As the field evolves rapidly with new research on evaluation metrics and interactive benchmarks, keeping tools aligned with academic advances drives continuous improvement in both evaluation criteria and agent design.
For developers building AI agents or extending MCP-based systems, investing in automated evaluation early pays dividends in debugging efficiency, user trust, and confident innovation. Production readiness requires guarantees of consistency and correct tool use - guarantees forged through systematic, rigorous testing adapted for the probabilistic world of AI.
Referenced Papers:
- Atil, B., et al. (2024). “Non-Determinism of ‘Deterministic’ LLM Settings.” arXiv preprint arXiv:2408.04667.
- Blackwell, R., et al. (2024). “Towards Reproducible LLM Evaluation: Quantifying Uncertainty in LLM Benchmark Scores.” arXiv preprint arXiv:2410.03492.
- Chen, S., et al. (2025). “AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents.” Proceedings of NeurIPS 2024.
- Lu, J., et al. (2024). “ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities.” arXiv preprint arXiv:2408.04682.
- Huang, J., et al. (2024). “UltraTool: Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios.” Proceedings of ACL 2024.
- Wang, J., et al. (2024). “AvaTaR: Optimizing LLM Agents for Tool Usage via Contrastive Reasoning.” Proceedings of NeurIPS 2024.
- Zhang, Y., et al. (2024). “RETAIN: Interactive Tool for Regression Testing Guided LLM Migration.” arXiv preprint arXiv:2409.03928.
- Mehta, S., et al. (2021). “A Comprehensive Assessment of Dialog Evaluation Metrics.” arXiv preprint arXiv:2106.03706.
Originally published at mcpproxy.app/blog/